Is a market trending or not? Even this simple question, which is at the heart of most of our thinking about markets, is not easy to answer. Definitions of trend are often subjective, depend on both timeframe (e.g., daily or intraday) and reference period (i.e., how far are we looking back?), and are generally somewhat unsatisfactory, in one way or another. I have been working to improve that situation, and I want to share some of my work with you today.
Calculating the Grimes Efficiency Ratio
One of the best ways to track intraday strength among several markets is to calculate the closing price as a percentage of the day’s range; it is intuitive that markets near the high of the day would be stronger, and those near the low would be weaker. When we look at other periods or want to evaluate trend strength over a period of time, the task is a little harder. One solution is to pick an arbitrary lookback period, and calculate the closing price as a percentage of the total (high to low) range prices covered over that time. This measure is the heart of the tool I am calling the Grimes Efficiency Ratio (GER). The chart below shows the closing price as a percentage of the last 20 ((I chose 20 as a starting point since it represents about a month’s lookback. Also, it corresponds, roughly, to the vertical grid lines on the chart, so it’s easier for you to evaluate visually.)) trading days’ range for every bar on the chart:
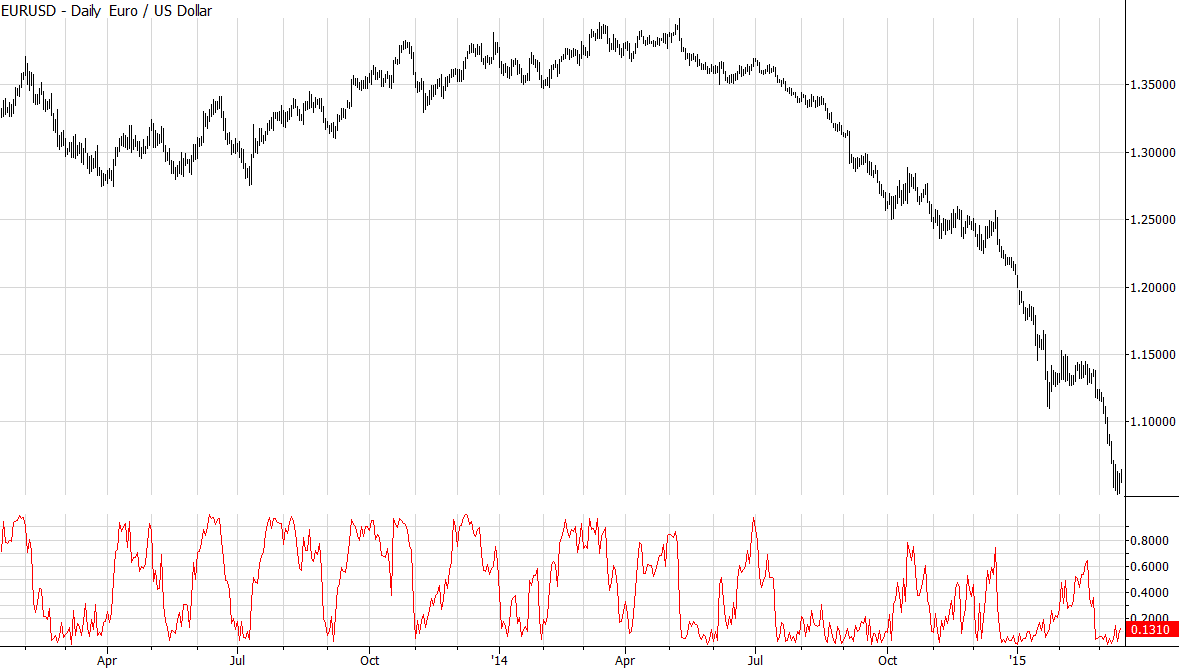
This is obviously a noise measure that can flip from 1.0, meaning the close is the high price achieved in the last month, to 0.0 on a single bar. It’s very difficult to extract useful information from something this noisy, but look what happens when we smooth it a bit, averaging the close as % range measure for each of the past 20 trading days:
![EURUSD with GER[20]](https://adamhgrimes.com/wp-content/uploads/2015/03/smoothed-eurusd.png)
How to use the GER
Initially, there are a few ways I would consider using this tool:
- Use it as a filter for rules-based strategies, but more work would need to be done to see if it is predictive. It does a great job of describing past trend conditions, but regimes change quickly, and a tool like this might do more harm than good.
- Rather than using as an entry filter, use to managing existing positions. For instance, perhaps a trailing stop could tighten faster as the GER falls.
- Rank multiple markets by GER and use it as an input in selecting best markets to trade.
- Use middle-ranked GER markets (which we would presume to be in trading ranges or consolidations) as breakout candidates or at least as a place to look for further screening.
- Use markets that have recently shown an extremely high or low GER, and now show a more moderate level, as potential pullback trades.
My point here is just to give you some ideas and some ways to think about a tool like this. There’s a lot more to be done, but these ideas might be a good starting points. While we’re at it, here’s something different.
A counter-intuitive use of the GER
Market psychology swings back and forth between extremes. We all know this, and some standard examples come to mind: a soaring market that crashes (extreme of trend direction), a quiet market that explodes with new volatility (volatility contraction), or a market that exhausts itself in a last-gasp, mighty trend thrust–these are common examples of extremes. Another extreme is simply the alternation between trending (without considering direction) and trading range. This tool captures this rhythm visually, but there’s more…
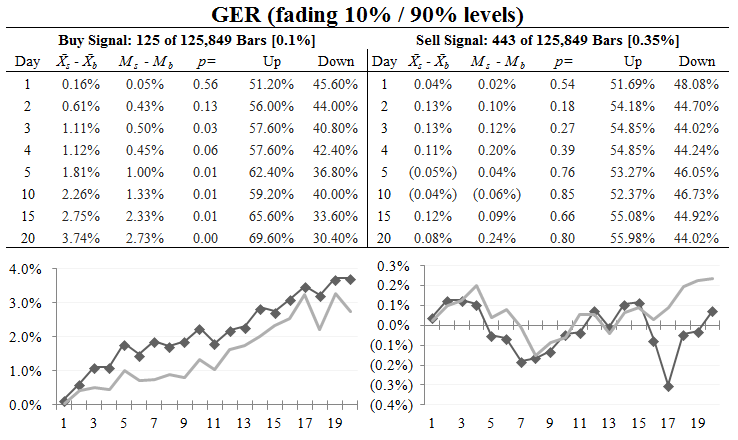
This tool was created to measure trend strength, but there is an edge to fading extremes of trends. The GER can be used in as an overbought/oversold indicator; the table above shows the results of fading an extreme level of the GER, only taking one trade every two weeks, on a basket of 50 stocks. Pay attention to the first column, which shows the outperformance over the baseline drift return: a staggering 3.74% over the next 20 trading days for the buy signal. This is a basket of stocks, and it’s normal to see a sell signal not perform as well, but we might have a little juice on the shorting side too. ((Consider statistical significance, which you can read in the “p=” column. Buys appear to be significant and sells do not, but, again, that asymmetry does not invalidate the tool, here at first glance.))
Here’s the code
Here is the code, in EasyLanguage format, with some comments.
inputs: lookback(20); vars: rng(0), crng(0), sumrng(0); rng = highest(h, lookback) - lowest(l, lookback); crng = iff(rng > 0,((c - lowest(l, lookback)) / rng), 0); //calculate close as % of range, catch divide by zero error sumrng = average(crng, lookback); plot1(sumrng);
If you make use of this, please let me know. I will continue to work on it and tweak it, and I just might find an interesting use for it.
(Note that there is an indicator called the Kaufman Efficiency Ratio, but it is quite different. It looks at the price change over a period of time, divided by the sum of the absolute price movements over that period. The idea here is to look at how far the market moved against how much it jiggled around, but the KER does not consider highs and lows. The GER represents a significantly different perspective, as it’s essentially an averaged percentile of price.)
Other examples
I will leave you with a few other examples on other markets:
![S&P 500 (cash) with GER[20]](https://adamhgrimes.com/wp-content/uploads/2015/03/GER-SP-500.png)
![Gold futures with GER[20]](https://adamhgrimes.com/wp-content/uploads/2015/03/GER-GC.png)
![Crude oil with GER[20]](https://adamhgrimes.com/wp-content/uploads/2015/03/GER-CL.png)
If I understand:
GER(20) = MovingAverage( Stochastic(20) , 20)
Basically, yes, using the core concept of the stochastic without the %K %D crossing. (Also, Williams %R is another similar take on the concept.) I think the interpretation here is probably where the value is–everyone has sliced and diced OHLC data so much there’s really very little new in terms of indicators.
But you still stick your name into it, of course…
But you still rushed in to give this your name, good job.
Is there already similar work and application of a tool like this, using both in a countertrend setting and as an assessment of trend strength? Kindly provide a reference, if so.
There’s very little new in simple analysis like this… everyone stands on the shoulders of people who have done work before us, but small differences in perspectives and application matter.
I’ve personally found many times the slight change in presentation can give you completely different insight into the data you are analysing.
http://qusma.com/2012/12/19/ibs-and-relative-value-mean-reversion/
In this case the author names it IBS, but as other reader mentions, this is just the old stochastics(period=20, k=1, d=1) and then you apply a revolutionary moving average over it.
The concept is ok, I’m just sick of people reinventing the same thing over and over again and tossing their name on it.
With all due respect, you’re mistaken… what the author calls the IBS is the position of the close within a single bar, and that’s quite a different measure.
There’s value in my work here, and I gave it all away for free. I posted the code. I’m not selling any indicators or anything, so I’m not sure why this sparked such a series of ranting posts from you. I provide the tool, a quick (but deep) statistical test of its utility, give a few ways to think about it, show a few examples, and give it away. Where’s the problem with this?
It’s all the same thing. Every trading idea is a rehash of something else. There’s nothing new under the sun.
Appreciate Your Insights & Help ! Thank You
@Dan
Having this huge internet at your disposal and spending your time on a website that annoys you, is either masochism or a complete lack of imagination.
I don’t think your attitude towards someone who just tries to share something with others, is fair.
well said. Trying to name a one-line-of-code indicator after yourself after it has already been discussed ad nauseum across the blogosphere for years? Awkward, at best.
Can’t wait for the GMA (Grimes Moving Average)
Yeah ! 1) Current Day Close With Relation to the Current Day Range & 2) Change in Current Day Close with Respective Previous day close & Current Day Range With Respect to Previous day Range gives good insights into the Position of the Balance of Power between the Bulls & Bears. Thank You for the Efficient Ratio 🙂
In other words, a SMA(close-runMin(20))/(runMax(20)-runMin(20)),20)
The interpretation may be one thing, I’m just concerned about the lag.
Ilya,
Exactly. The lag is the key issue here.
Adam,
– Why did you choose to make it a mean-reverting indicator, rather than making it a momentum/trend following one?
While there is nothing revolutionary in the approach itself, I guess your lines of thought that brought to this approach and your analysis of how this approach can be applied definitely brings value.
We’re doing quant stuff here, so choosing lag parameter in a quant driven world, because “it represents about a month’s lookback” seems a bit naiive. Also p-levels do not translate directly into pnl. It’s not about predicting a move with certain probability, it’s about the math expectation of a trade. Consider predicting small moves with 70% probability a then having huge losses every time you are wrong (ex: short naked options).
I am sure that using a tight stop with small lag on a trending time series like Oil can produce even better results
Thanks!
No implication that a p-value, or even that a statistical edge would translate into P&L–you are correct.
As for lookback period, I don’t think a choice of 20 is naive–it’s arbitrary. Pick any number you like, but I wouldn’t get stock trying to optimize that number or anything. It was chosen as much for the visual representation on that post as anything else, I suppose.
Make sure you’re thinking in large sample sizes. A trend like we’ve seen in oil is certainly an outlier and you might not (or you might) want to focus attention on developing something for that environment.
Just because you’re not doing any optimization does not mean that you are optimization bias free. Arbitrary or random number is as good as a heavy optimized one.
My point is that rather taking a random number, the number should come from time series analysis. You have a double lag, essentially. So having “20” as input on a highly trending time series or non stationary MR time series with half life significantly less than 20 should result in poor performance. Despite having a decent method, using a sub-optimal parameter will lead to under performance. Just because you don’t want to fall into optimization trap, does not mean you should be using one parameter for every market and time frame.
Now optimization does not mean using 23 vs 20 because it gives extra points in sharpe ratio, but rather looking at a range of parameters like 15-25 and checking if pnl distribution within this range is acceptable, no spikes, etc… Such approach might lead to conclusion that 15-25 range is ok for mean reversion and 90 – 120 is ok for momentum for a certain market, and that would be totally fine. Think of oscillating MR time series with big drift – you are either extracting small price retracements with tight stops, or catching the drift with bigger stops and accepting the volatility. Example – Natural Gas futures.
That’s just my 2c on taking your lines of thought a bit further…
Pingback: The Whole Street’s Daily Wrap for 3/17/2015 | The Whole Street
Hi Adam – I’ve been thinking about “scoring” bars over n-periods and weighting old vs new data etc. The score would be calculated along the lines of +1 if price made a high > yesterday high, +1 if closed in top 20% of bar,….etc. Then using a cumulative score and asking questions like how often is today’s low taken out when n-period score is -6? Are you familiar with anyone who has done studies like this. Also as an aside should I learn python or R?
This post says that buying stocks when ger(20) fails below 10 and sell them 20 days later, will generate a profit in 69.6% of trades. Was anyone able to replicate this? I wasn’t. Thanks